Amazon Athena uses a managed Data Catalog to store information and schemas about the databases and tables that you create for your data stored in Amazon S3. In the case of tables partitioned on one or more columns, when new data is loaded in S3, the metadata store does not get updated with the new partitions. You need to explicitly add the partitions in the metadata store.
Refer : “AWS Partitions” for detailed information.
In this article, we will look at the various approaches which help us achieve adding partitioning programmatically.
To begin with, the basic commands to add a partition in the catalog are :
MSCK REPAIR TABLE
or
ALTER TABLE ADD PARTITION
To keep Athena Table metadata updated without the need to run these commands manually we can use the following :
- A programmatic approach by running a simple Python Script as a Glue Job and scheduling it to run at a desired frequency
- Glue Crawlers

What are Partitions?
In AWS S3, partitions play an important role when querying data in Amazon Athena/Presto or Redshift Spectrum since, it limits the volume of data scanned, dramatically accelerating queries and reducing costs.
Partitions are logical entities in a metadata store such as Glue Data Catalog or Hive Metastore which are mapped to Folders which are physical entities where data is stored on S3,
Partitions in itself would be a completely different topic to cover sometime later. For now lets just understand that it’s the physical division of data in S3 similar to a folder structure in file system where the column on which the partition is created becomes the object (folder) under which the data set would be stored.
Dealing with Dynamic Partitions
While creating a table in Athena we mention the partition columns, however, the partitions are not reflected until added explicitly, thus you do not get any records on querying the table.
In the scenario where partitions are not updated frequently, it would be best to run MSCK REPAIR TABLE to keep the schema in sync with the complete dataset.
For use cases where streaming data or continuous data is added and partition is normally done on a date column or new partitions are created on a daily/weekly/monthly basis we could use a GLUE Crawler (can be expensive in case of very huge data sets and files).
Another way that I find to be more cost-effective would be to have a python script to compare the Athena metadata with the S3 data structure and add the new partitions without having the overhead of scanning all the files in the bucket. This is the method that I am going to focus on in this article.
Pseudo Code for a high-level overview of the process :
- Passing parameters through ETL Job to set
'region'= AWS Region
'database'= Athena Database
'tableName'= Athena table to update partitions
'athenaResultBucket'= Temporary bucket to hold athena query result
'athenaResultFolder'= Temporary folder to store athena query result
's3Bucket'= S3 Bucket from where the table is created
's3Folder'= S3 Folder from where the table is created
2. Scan AWS Athena schema to identify partitions already stored in the metadata.
3. Parse S3 folder structure to fetch complete partition list
4. Create List to identify new partitions by subtracting Athena List from S3 List
5. Create Alter Table query to Update Partitions in Athena
Understanding the Python Script Part-By-Part
import boto3 import re import time import botocore import sys from func_timeout import func_timeout, FunctionTimedOut from awsglue.utils import getResolvedOptions
boto3 is the most widely used python library to connect and access AWS components.
getResolvedOptions is used to read and parse Glue job parameters.
args = getResolvedOptions(sys.argv, ['region', 'database', 'tableName', 'athenaResultBucket', 'athenaResultFolder', 's3Bucket', 's3Folder'])
params = {
'region': args['region'],
'database': args['database'],
'tableName': args['tableName'],
'athenaResultBucket': args['athenaResultBucket'],
'athenaResultFolder': args['athenaResultFolder'],
's3Bucket': args['s3Bucket'],
's3Folder': args['s3Folder'],
'timeout': int(args['timeout']) # in sec
}
print("Parameters : ")
print(params)
print("----------------------------------")
print()
Parameters can be hard coded inside the params or passed while running the Glue Job.
s3Client = boto3.client('s3', region_name=params['region'])
s3Resource = boto3.resource('s3')
athenaClient = boto3.client('athena', region_name=params['region'])
Clients for connecting to AWS Athena and AWS S3.
# Check if Bucket Exists s3CheckIfBucketExists(s3Resource, params["athenaResultBucket"])
The main execution of the python scripts starts from this line.
def s3CheckIfBucketExists(s3Resource, bucketName):
try:
s3Resource.meta.client.head_bucket(Bucket=bucketName)
print("Athena Bucket exists")
print("----------------------------------")
print()
except botocore.exceptions.ClientError as e:
print("Athena Bucket does not exist.")
print(e)
print("----------------------------------")
location = {'LocationConstraint': params['region']}
s3Client.create_bucket(Bucket=params['s3Bucket'], CreateBucketConfiguration=location)
print()
print("Athena Bucket Created Successfully.")
print()
Function checks if bucket exists in S3 to store temporary Athena result set, if not we can create a temporary bucket using s3client or throw an error depending on the requirement.
def athena_query(athenaClient, queryString):
response = athenaClient.start_query_execution(
QueryString=queryString,
QueryExecutionContext={
'Database': params['database']
},
ResultConfiguration={
'OutputLocation': 's3://' + params['athenaResultBucket'] + '/' + params['athenaResultFolder'] + '/'
}
)
return response
The above function is used to run queries on Athena using athenaClient i.e. “SHOW PARTITIONS foobar” & “ALTER TABLE foobar ADD IF NOT EXISTS PARTITION(year=’2020', month=03) PARTITION( year=’2020', month=04)”.
athenaClient will run the query and the output would be stored in a S3 location which is used while calling the API. Output path is mentioned in ResultConfiguration :: OutputLocation key
def athena_to_s3(athenaClient, params):
queryString = "SHOW PARTITIONS " + params["tableName"]
print("Show Partition Query : ")
print(queryString)
print("----------------------------------")
print()
execution = athena_query(athenaClient, queryString)
execution_id = execution['QueryExecutionId']
state = 'RUNNING'
while (state in ['RUNNING', 'QUEUED']):
response = athenaClient.get_query_execution(QueryExecutionId=execution_id)
if 'QueryExecution' in response and 'Status' in response['QueryExecution'] and 'State' in response['QueryExecution']['Status']:
state = response['QueryExecution']['Status']['State']
if state == 'FAILED':
print(response)
print("state == FAILED")
return False
elif state == 'SUCCEEDED':
s3_path = response['QueryExecution']['ResultConfiguration']['OutputLocation']
filename = re.findall('.*\/(.*)', s3_path)[0]
return filename
time.sleep(1)
return False
This function will call the athena_query method and wait till it is executed on Athena. The result set is a text file stored in temp S3 {bucket}.{folder}. Function returns the temporary filename for parsing further. It will return ‘false’ boolean if something goes wrong while execution
# Fetch Athena result file from S3 s3_filename = athena_to_s3(athenaClient, params)
A simple calling to the mentioned functions to fetch the result filename for parsing.
# Fetch Athena result file from S3
try:
s3_filename = func_timeout(params['timeout'], athena_to_s3, args=(athenaClient,params))
except FunctionTimedOut:
print("Athena Show Partition query timed out.")
print()
print("#~ FAILURE ~#")
print()
print()
raise
print("Athena Result File At :")
print(params['athenaResultBucket'] + '/' + params["athenaResultFolder"]+'/'+s3_filename)
print("----------------------------------")
print()
As per my usecase, I had to encapsulate the Athena query function with a timeout. For this, I have used a very cool, neat and easy python library
func_timeout(Author: Tim Savannah)
NOTE : To add external library to Glue Job is itself a neat trick to cover in a separate blog (Will update once its ready)
You can use either of the above two approaches (direct calling or with function timeout).
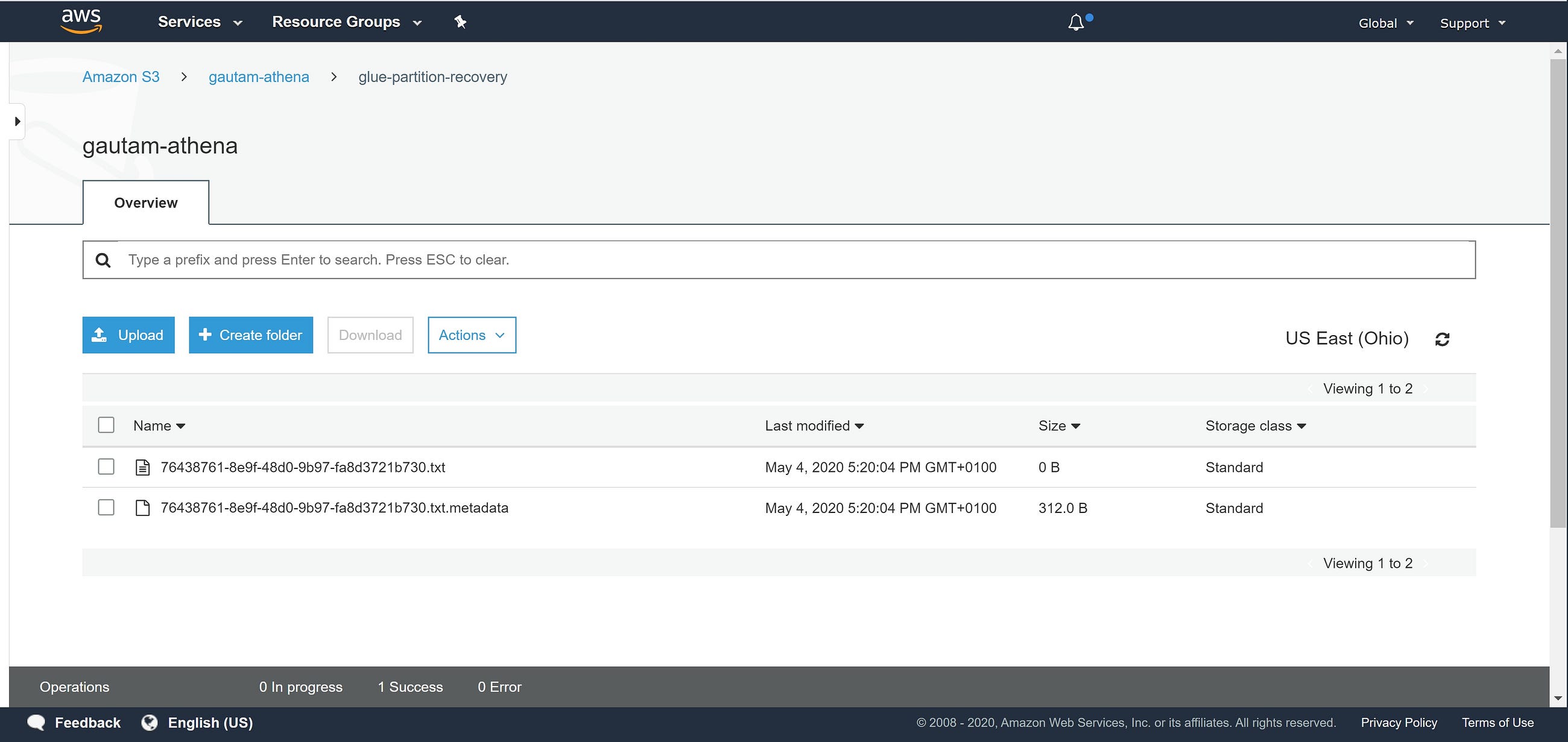
Athena Show Partition query output file on S3
# Read Athena Query Result file and create a list of partitions present in athena meta
fileObj = s3Client.get_object(
Bucket=params['athenaResultBucket'],
Key=params['athenaResultFolder']+'/'+s3_filename
)
fileData = fileObj['Body'].read()
contents = fileData.decode('utf-8')
athenaList = contents.splitlines()
print("Athena Partition List : ")
print(athenaList)
print("----------------------------------")
print()
Athena query result is a .txt format file hence, the result has to be parsed in a list for comparison to identify the newly created partitions. I have used the splitlines() method to separate the resultset into a list.
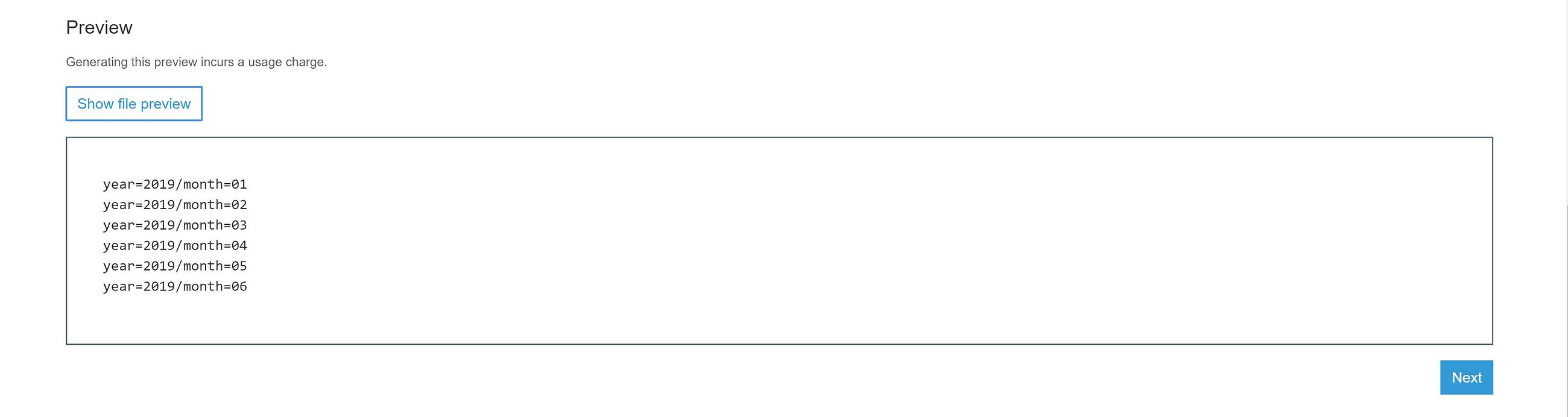
Athena result file preview
def s3ListObject(s3, prefix):
resultList = []
result = s3.list_objects_v2(
Bucket=params['s3Bucket'],
Delimiter='/',
Prefix=prefix
)
resultList.extend(result.get('CommonPrefixes'))
while (result['IsTruncated']):
result = s3.list_objects_v2(
Bucket=params['s3Bucket'],
Delimiter='/',
Prefix=prefix,
ContinuationToken=result['NextContinuationToken']
)
resultList.extend(result.get('CommonPrefixes'))
return resultList
The above function is used to parse the S3 object structure to gather the partition list using the aws sdk list_objects_v2 method. Pagination of S3 objects is handled using the NextContinuationToken as AWS API returns max 1000 objects in a single API call.
# Parse S3 folder structure and create partition list
prefix = params['s3Folder']
yearFolders = s3ListObject(s3Client, prefix)
monthList = []
for year in yearFolders:
result = s3Client.list_objects_v2(
Bucket=params['s3Bucket'],
Delimiter='/',
Prefix=year.get('Prefix')
)
monthList.extend(result.get('CommonPrefixes'))
s3List = []
for thingType in monthList:
string = thingType.get('Prefix').replace(params['s3Folder'], "")
s3List.append(string.rstrip('/'))
print("S3 Folder Structure At :")
print(params['s3Bucket'] + '/' + params['s3Folder'])
print("----------------------------------")
print()
print("S3 Partition List : ")
print(s3List)
print("----------------------------------")
print()
This is a part which should be tweaked depending on your partition level. This example has 2 levels of partitions i.e. year and month.
Looping over the S3 structure by fetching CommonPrefixes and iterating over them again to fetch the inner partition list to have the final partition list.
Fetching the CommonPrefixes will avoid parsing through the entire S3 file structure thus making it faster and leaner.
# Compare Athena Partition List with S3 Partition List
resultSet = set(s3List) - set(athenaList)
print("Result Set : ")
print(resultSet)
print("----------------------------------")
print()
Set subtraction of Athena partition list from S3 partition list would give us the list of newly created / missing partitions
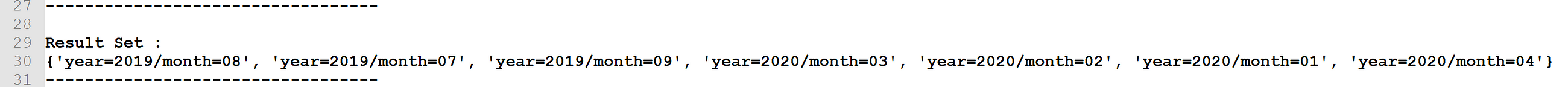
Python output for new/missing partition list
# Create Alter Query for Athena
if len(resultSet) != 0:
queryString = "ALTER TABLE " + params['tableName'] + " ADD IF NOT EXISTS PARTITION(" + repr(resultSet) + ")"
queryString = queryString.replace("{", "")
queryString = queryString.replace("}", "")
queryString = queryString.replace(",", ") PARTITION(")
queryString = queryString.replace("'", "")
queryString = queryString.replace("year=", "year='")
queryString = queryString.replace("/", "', ")
print("Alter Query String : ")
print(queryString)
print("----------------------------------")
print()
# Run Alter Partition Query
execution = athena_query(athenaClient, queryString)
if execution['ResponseMetadata']['HTTPStatusCode'] == 200:
# Temp Folder Cleanup
cleanup(s3Resource, params)
print("*~ SUCCESS ~*")
else:
print("#~ FAILURE ~#")
else:
# Temp Folder Cleanup
cleanup(s3Resource, params)
print()
print("*~ SUCCESS ~*")
Finally comes the part where the Alter Table partition query is formed by creating a complete query string and altering the string as per the syntax.
NOTE : To add variations to schema I have set year column to be string and month column to be int thus the query had to be formed respectively

ALTER TABLE foobar ADD IF NOT EXISTS PARTITION(year=’2019′, month=08) PARTITION( year=’2019′, month=07) PARTITION( year=’2019′, month=09) PARTITION( year=’2020′, month=03) PARTITION( year=’2020′, month=02) PARTITION( year=’2020′, month=01) PARTITION( year=’2020′, month=04)
The last piece of code is encapsulated in an if..else block to check if the result set is empty to avoid triggering an empty query.
def cleanup(s3Resource, params):
print('Cleaning Temp Folder Created: ')
print(params['athenaResultBucket']+'/'+params["athenaResultFolder"]+'/')
print()
s3Resource.Bucket(params['athenaResultBucket']).objects.filter(Prefix=params["athenaResultFolder"]).delete()
print('Cleaning Completed')
print("----------------------------------")
print()
# s3Resource.Bucket(params['athenaResultBucket']).delete()
And lastly the cleanup()method is used to delete the temporary result file, Athena folder (and Bucket if required — uncomment the last line)
Complete Python Script
Can be found at github open repository.
Script OUTPUT :

After all the geeky coding comes the most easy part of click-click-run-done. Create a Glue job using the given script file and use a glue trigger to schedule the job using a cron expression or event trigger.
Thank you for reading till the end. Hope you found it worthy. I am not an AWS expert but pursuing to be one. Just shared my personal experience working on a POC which I thought would help others like me. Do like the blog, comment your feedback and improvements and also let me know if you need any help understanding it. Please follow for more such easy and interesting write ups. This would motivate me to keep writing and sharing my experiences.
Till then Keep Smiling and Keep Coding ✌️😊 !!